徏旜嫥偺儁乕僕
08擭1寧25擔丂傗偭傁傝嬨妱偑偨偺愢柧偑偮偔劅劅乽斊嵾偲幐嬈棪乿懕曬丂(1寧28擔廋惓)
嵟怴暘愅寢壥偁傝仺09擭3寧19擔斉
捛婰丗偙偺儁乕僕傪傾僢僾儘乕僪屻丄旐愢柧曄悢傪愢柧曄悢偵巊偭偨夞婣幃偱偼丄岆嵎偺宯楍憡娭偺敾掕偵僟乕價儞丒儚僩僜儞斾偼巊偊側偄偲偄偆偙偲傪僂僃僽忋偱敪尒偟丄栴栰峗堦偝傫偵揹巕儊乕儖偱妋擣偟偨偲偙傠丄偦偺捠傝偩偲偄偆偙偲偑傢偐傝傑偟偨丅偁傝偑偲偆偛偞偄傑偡丅
丂偙偺応崌偺宯楍憡娭偺敾掕偼丄乽僟乕價儞偺h乿偲偄偆傕偺傪梡偄傞偲偄偆偙偲傪丄僂僃僽傪挷傋偰恖惗偱巒傔偰抦傝傑偟偨丅壓婰偺儌僨儖X丄儌僨儖Y偼丄偙傟偵偁偰偼傑傝傑偡偺偱丄僟乕價儞丒儚僩僜儞偱偼側偔偰丄僟乕價儞偺h傪梡偄偰敾掕偟側偗傟偽側傝傑偣傫丅徻偟偔偼丄
http://www.eco.osakafu-u.ac.jp/~kazuhisa/e8.htm
http://www.csus.edu/indiv/j/jensena/mgmt105/durbin-h.htm仼帺暘偺塸岅椡偑偍偐偟偄偺偐丄婣柍壖愢偺愢柧偑斀懳偺傛偆側婥偑偡傞丅
http://ht.econ.kobe-u.ac.jp/~tanizaki/class/2005/econome.grad/0611/dw.pdf
丂偙偺嵟屻偺偼丄戝妛堾偺崰偺愭攜丄扟嶈媣巙偝傫偺旕忢偵暘偐傝傗偡偄嫵嵽偱偡丅偙傟傪尒偰杮恖偵揹榖偱栤偄崌傢偣偨傜丄恊愗偵嫵偊偰偄偨偩偄偰偁傝偑偲偆偛偞偄傑偟偨丅専徹寢壥偼壓偵彂偒崬傫偱偁傝傑偡丅儌僨儖X丄儌僨儖Y偲傕偵丄宯楍憡娭偼側偄偲尒偰傛偄丄OK偩偲偄偆偙偲偵側傝傑偡丅偲傝偁偊偢傎偭偲堦埨怱偱偡丅
丂偮偄偱偵丄僟乕價儞丒儚僩僜儞斾傪巊偭偨僥僗僩傕丄忋偺扟嶈偝傫偺昞側偳傪巊偭偰尩枾偵傗傝側偍偟偰傒傑偟偨丅偐側傝娒偄敾抐傪偟偰偄偨偙偲偑傢偐偭偰偡傒傑偣傫丅埲壓偵廋惓偟偰偍偒傑偡丅(08擭1寧28擔)
丂擔崰丄愘僒僀僩偵壗偺斀墳傕側偄偙偲傪枴婥側偄偲巚偭偰偄偨丅偟偐偟慜夞偺僄僢僙乕偑乽偼偰側僽僢僋儅乕僋乿偱堦帪540廤傔偨傝丄乽傾儊乕僶僯儏乕僗乿偵庢傝忋偘傜傟偨傝丄偨偔偝傫偺娭楢僄儞僩儕乕傪偄偨偩偄偨傝偡傞偲丄戝曄偁傝偑偨偄偲巚偄偮偮傕丄枅擔悽娫偺斀墳偑婥偵側偭偰婥偵側偭偰偟偐偨側偄丅偦傟偱丄偟傚偭偪傘偆帪娫傪偮傇偟偰偟傑偭偰丄寢峔僗僩儗僗偵側偭偨傝偡傞丅帺暘側偑傜彑庤側傕偺偱偁傞丅
丂偦傟偱偮偄偮偄懕偒偺暘愅偵偺傔傝偙傫偩傝偟偰偟傑偆丅壓偵彂偄偨偲偍傝丄慜夞偺僄僢僙乕偺暘愅偵偼乽岆嵎偺宯楍憡娭乿偲偄偆栤戣偑偁偭偨偺偱丄偪傖傫偲夝寛偟側偄偲婥偑偍偝傑傜側偐偭偨偺偱偁傞丅偁偲偱偍尒偣偟傑偡偺偱丄惪偆屼婜懸丅乽嬨妱乿偺柌嵞傃偲捛偄媮傔傞摤偄偺婰榐偱偁傞丅
丂杮摉偼偙傫側愱栧奜偺偙偲傪偟偰偄傞壣偼側偄偺偱偁傞丅偲偄偭偰傕丄嵎偟敆偭偰偄傞巇帠偺懡偔偼愱栧奜偺偙偲側偺偩偑丅崱寧拞偺庡梫側傕偺偩偗偱傕暲傋偰傒傞偲偙傟偩偗偁傞丅
丒妛撪妛弍嶨帍偺榑暥尨峞丅妛晹偺尋媶強偺強挿偐傜偺偛梡柦偱偁傞丅偙傟偼丄崱傑偱抧堟偐傜惪晧偭偰偒偨媣棷暷抧嬫偱偺娤岝僐儞儀儞僔儑儞偺宱嵪攇媦岠壥暘愅偵偮偄偰慡晹傑偲傔傞巇帠偱偁傞丅怴擭搙偐傜戝妛傪曄傢傞偺偱偙偺巇帠偼屻擟偵堷偒宲偖偨傔丄儅僯儏傾儖偲偟偰巊偊傞傛偆偵丄崸愗挌擩偵彂偐側偗傟偽側傜側偄丅掲傔愗傝偼夁偓偰偄傞偺偩偑丄摨偠崋偵彂偔愭惗偺堦恖偲僇儖僥儖傪寢傫偩偐傜丄棃廡傑偱側傫偲偐堷偒墑偽偣偦偆偩丅
丒戝柎揷帇嶡偺曬崘僒僀僩嶌惉丅12寧偵幚巤偟偨戝柎揷偺傑偪偯偔傝帇嶡僀儀儞僩偑丄暥妛晹H嫵庼偺嫟摨尋媶偺梊嶼偱傗偭偨偺偱丄嫵庼偐傜曬崘傪憗偔傑偲傔傞傛偆尵傢傟偰偄傞丅儂乕儉儁乕僕偵偡傞傓偹尵偭偰偁傞偺偱丄憗偔傗傜側偄偲丅慡慠庤傪晅偗偰偄側偄丅
丒巗媍夛媍堳偺屻墖夛偺嶐擭偺寛嶼丅2寧11擔偺憤夛偵傓偗偰丄2寧弶摢偵塣塩夛媍偑偁傞偺偱丄偦傟傑偱偵娫偵崌傢偣偰娔嵏傪庴偗側偄偲丅
丒偙偺儂乕儉儁乕僕偑丄戝妛傪堏傞偺偱弔偵偼戝妛偺僒乕僶乕偐傜捛偄弌偝傟傞丅憗傔偵怴偟偄偲偙傠偵堏偟偲偐側偄偲丄堏揮偑廃抦偱偒側偄丅偲偙傠偑崱帺戭偱巊偭偰偄傞働乕僽儖僥儗價偺僒乕僶乕偵偼丄巗媍夛媍堳偺屻墖夛偺儂乕儉儁乕僕傪擖傟偰偄偰偄偭傁偄偱偁傞丅屻幰偺曽傪丄怴偟偄僒乕僶乕傪尒偮偗偰堏偝側偗傟偽側傜側偄偺偩偑丄帺戭偺傕偄偭偟傚偵愗傝懼偊偨偄婥傕偡傞丅屻墖夛偺曽偼2寧偺塣塩夛媍偱巟弌偺彸擣傪傕傜偆偺偵娫偵崌偆傛偆偵丄偄傠偄傠斾妑専摙偟偰憗偔堏偝側偄偲偄偗側偄偺偩偑丅
丒妛惗偺懖榑偵偁偨傞榑暥巜摫1審丅傑偩摴嬝偑掕傑偭偰偄側偄丅崲偭偨丅
丒棫柦娰戝妛偺僔儔僶僗嶌惉丅偄傠偄傠嵶偐偄偧丅傛偔巇慻傒偑傢偐傜側偄偺偵丅杮擔掲傔愗傝丅
丒掕婜帋尡丒儗億乕僩椶偺嵦揰丅
丒2寧4擔偵戝嶃偱傑偪偯偔傝偲彜恖摴偵娭偡傞岞奐尋媶夛傪庡嵜偡傞偙偲偵側偭偨偺偱偦偺弨旛丅
嵶偐偄偙偲偼傑偩傑偩偁傞偑丅妛晹挿偑尋媶幒傪巆偟偰偔傟偨偺偑彆偐偭偨丅堷偒暐傢側偗傟偽側傜側偄側傜戝巇帠偩偭偨丅偱傕崱廡枛偼壨忋敚徿彠椼徿偺庼徿幃偱巕楢傟偱丄崱斢偐傜搶嫗偵峴偔偺傛丅愭廡枛偼搚擔偲傕偵僙儞僞乕帋尡偺娔撀偱偮傇傟偨偟丄偦偺忋挰撪偺怴擭夛偑偁偭偨傝偟偨偟丅偼偁丅
******************************************
丂偝偰丄慜夞偺僄僢僙乕偵懳偟偰丄傒側偝傑偐傜偄偨偩偄偨偦偺屻偺庡側揥奐偵偼師偺傛偆側傕偺偑偁傝傑偡丅
1寧16擔丂svnseeds偝傫偑丄G7彅崙偵偮偄偰丄斊嵾棪偲幐嬈棪偺憡娭偺崙嵺斾妑傪偝傟偰偄傑偡丅幚摥5帪娫偺椡嶌偱偡丅
http://d.hatena.ne.jp/svnseeds/20080116
1寧17擔丂eliya偝傫偑丄斊嵾偺庬椶暿偵幐嬈棪偲偺憡娭傪暘愅偝傟偰偄傑偡丅愞搻偼憡娭偡傞偑嶦恖偼憡娭偟側偄丅
http://d.hatena.ne.jp/eliya/20080117
1寧17擔丂栴栰峗堦偝傫偑丄僽儘僌偱岆嵎崁偑夞婣暘愅偺慜採傪枮偨偟偰偄傞偐偛巜揈壓偝偄傑偟偨丅憗懍丄僟乕價儞丒儚僩僜儞斾傪寁嶼偟偰傒偨傜丄慜夞偺僄僢僙乕偺暘愅偼丄岆嵎偺宯楍憡娭偑偁傞偺偱惓妋偱側偄偙偲偑柧傜偐偵側傝傑偟偨丅僈僢僋儕丅徻偟偔偼壓偺僽儘僌偺僐儊儞僩棑傪嶲徠偺偙偲丅栴栰偝傫偼斊嵾丒幐嬈娫偺憡娭偼戝嬝偱偼娫堘偄側偄偲尒偰偄傜偭偟傖偄傑偡丅
http://d.hatena.ne.jp/koiti_yano/20080117
1寧18擔丂戝抾暥梇愭惗偑僽儘僌偱庢傝忋偘偰壓偝偄傑偟偨丅慜夞偺僄僢僙乕偱巹偼丄愭峴尋媶偑尒摉偨傜側偄偲偄偆榖偺拞偱丄戝抾愭惗偑偳偙偐偱偙偺暘愅傪傗偭偰偄傞偼偢偲梊憐偟傑偟偨丅幚偼偦傟偼傑偩側偝偭偰偄側偐偭偨偺偱偡偑丄幮夛妛幰偺捗搰徆姲巵偑亀擔杮楯摥尋媶嶨帍亁偵敪昞偟偨乽幐嬈丒斊嵾丒擭楊乿偲偄偆愭峴尋媶偑偁傞偙偲傪徯夘偝傟偰偄傑偡丅
http://ohtake.cocolog-nifty.com/ohtake/2008/01/post_f38d.html
捗搰愭惗偺榑暥偼偙偪傜丄
http://db.jil.go.jp/cgi-bin/jsk012?smode=dtldsp&detail=F2003080121&displayflg=1
偙傟偼丄2001擭傑偱偺僨乕僞傪巊偭偰偄偰丄幐嬈棪偑嵟埆傑偱払偟偰偐傜尭傝弌偟偨嵟怴悢擭娫偑傑偩娷傑傟偰偄傑偣傫丅傑偨乽擣抦審悢乿偵婎偯偔棪偱偼側偔偰丄乽専嫇棪乿傪巊偭偰偄傞偺偱丄傗傗幚徹寢壥偼埆偔側傞傛偆偱偡丅偟偐偟丄擭楊暿丄斊嵾庬暿偵暘偗丄傾乕儌儞儔僌庤朄傪巊偆側偳丄偐側傝棫偪擖偭偨徻偟偄暘愅傪偟偰偄傑偡(斊恖偑傢偐傜側偄偲擭楊偑傢偐傜側偄偺偱乽専嫇棪乿傪巊偆傎偐側偄偺偱偟傚偆)丅嫮搻傗愞搻偑幐嬈棪偲偺憡娭偑桳堄偱丄摿偵拞崅擭偺曽偑憡娭偑崅偔側傞偙偲偑帵偝傟偰偄傑偡丅
1寧18擔丂慜擔偺栴栰偝傫偺巜揈傪庴偗偰丄svnseeds偝傫偑16擔偺暘愅偺僟乕價儞丒儚僩僜儞斾傪挷傋偨傜丄傗偼傝岆嵎偺宯楍憡娭偑偁傞偙偲偑傢偐傝傑偟偨丅巆擮偱偡丅16擔偺僄儞僩儕乕偺捛婰傪偛棗壓偝偄丅戝嬝偱偼娫堘偄側偄偲巚偄傑偡偑丅
丂偝傜偵丄暷崙偺斊嵾庬暿偺幐嬈棪偲偺憡娭傪暘愅偝傟偰偄傑偡丅愞搻丄嫮搻偩偗偱偼側偔偰嶦恖傕憡娭偑偁傝偦偆偱偡偑丄傗偼傝僟乕價儞丒儚僩僜儞斾偑掅偄偙偲偑巆擮偱偡丅
http://d.hatena.ne.jp/svnseeds/20080118
1寧18擔丂eliya偝傫偑丄17擔偺斊嵾偺庬椶暿偺幐嬈棪偲偺憡娭暘愅偵娭偟偰丄岆嵎偺宯楍憡娭傪廋惓偟偨暘愅傪偝傟偰偄傑偡丅Prais-Winsten朄偲偄偆傜偟偄丅巹偼傛偔抦傝傑偣傫丅偦偺寢壥丄傗偼傝嫮搻丄愞搻偼偲偰傕桳堄側憡娭偑幚徹偝傟傑偟偨丅17擔偺暘愅偺抜奒偱偼岎捠帠屘傗婾憿傕幐嬈棪偲偺憡娭偑桳堄偲偝傟傑偟偨偑丄偦傟偼桳堄惈偑側偔側傝傑偟偨丅嶦恖傗朶峴側偳傕傗偼傝桳堄側憡娭偑娤嶡偝傟側偐偭偨偲偄偆偙偲偱偡丅
http://d.hatena.ne.jp/eliya/20080118/1200705999
丂幚偼丄嶦恖偲幐嬈棪偲偺憡娭偵偮偄偰偼丄PyTest偝傫偑1寧16擔偺僽儘僌偱丄1994擭偐傜2006擭傑偱偺僨乕僞傪巊偄丄嶦恖棪丄嶦恖擣抦審悢偲傕偵丄幐嬈棪偲偺娫偵桳堄側憡娭偑偁傞偙偲傪尒偄偩偟偰偄傑偡丅
http://d.hatena.ne.jp/PyTest/20080116/1200482273
丂幚徹婜娫偺堘偄側偳偑eliya偝傫偲偺寢榑偺堘偄偵偮側偑偭偰偄傞偺偩偲巚偄傑偡偑丄偙偺栤戣偼崱擔偺僄僢僙乕偱傕屻偵庢傝忋偘傑偡丅
丂偲偙傠偱丄偙偺PyTest偝傫偺僄儞僩儕乕偼丄懕偔丄
http://d.hatena.ne.jp/PyTest/20080116/1200469535
傕娷傔偰丄慜夞偺僄僢僙乕偺捛婰偱怗傟傑偟偨娗夑峕棷榊偝傫偺乽掁傝僱僞乿(乽寈嶡偑幐嬈棪偵崌傢偣偰擣抦審悢傪憖嶌偡傞乿)傪恀柺栚偵庴偗庢偭偰斀榑偟偨傕偺偱偡丅娗夑偝傫帺恎偼杮婥偱側偐偭偨偺偱偡偑丄偙傟傪恀柺栚偵怣偠偨恖偼懡偄傛偆側偺偱丄偦偆偄偆恖払岦偗偵偼偲偰傕桳梡側婰帠偩偲巚偄傑偡丅
******************************
丂偙偙偱丄偄偔偮偐偄偨偩偄偨僐儊儞僩傗偛斸敾偵偍墳偊偟偰偍偙偆偲巚偄傑偡丅
丂傑偢丄幐嬈棪仺斊嵾偲偄偆場壥娭學偱偼側偔偰丄斊嵾傪偍偐偟偰僋價偵側傞偐傜幐嬈棪偑憹偊傞偺偱偼側偄偐偲偄偆巜揈傪偲偒偳偒尒偐偗傑偟偨偑丄偦傟偼偁傝摼側偄偲巚偄傑偡丅幐嬈偺傎偲傫偳偼丄恖堳惍棟偺偨傔偵僋價偵側偭偨傝戅怑偵捛偄崬傑傟偨傝丄搢嶻偟偨傝丄怴懖幰偑廇怑岥偑側偐偭偨傝偟偰惗傒弌偝傟傞傕偺偱偁偭偰丄斊嵾傪斊偟偨偐傜僋價偵側傞側傫偰傕偺偼慡懱偺摦岦偵塭嬁傪梌偊傞検偱偼偁傝傑偣傫丅幐嬈棪偺慡懱揑摦岦偼埑搢揑偵宨婥偺忬懺偱寛傑偭偰偄傞偺偱偡丅
丂偦傟偐傜丄幐嬈偲斊嵾椉曽偵塭嬁傪梌偊傞戞嶰偺梫場偑偁偭偰丄偙偆偟偨場壥娭學偑娤嶡偝傟傞偺偱偼側偄偐偲偄偆偛堄尒傕懡偄偱偡丅
丂巹偺僛儈偼摑寁偺僛儈偱傕寁検偺僛儈偱傕側偔丄IS-LM偺傛偆側儅僋儘宱嵪棟榑偱宨婥傪榑偠傞偺偑栚揑偱丄惔悈嶇婓孨偼乽宨婥偲斊嵾偺娭學傪挷傋偨偄乿偲偄偆偺偑栤戣堄幆偱偟偨丅偦偟偰榑暥偺寢榑偼丄儅僋儘宱嵪惌嶔偭偰愑擟廳戝偩傛偹偲偄偆傕偺偱偡丅戞嶰偺梫場偑丄戝揤嵭傗愴嵭偱傕偁偭偨側傜偽暿偱偡偑丄尰幚偵偼傕偟偁偭偨偲偟偰傕丄宨婥偵娭楢偟偨傕偺埲奜偵偼峫偊傜傟側偄偲巚偄傑偡丅幐嬈棪偼晄宨婥傪昞偡巜悢偖傜偄偺埵抲晅偗偱傕丄偙偺尋媶偵偲偭偰偼廫暘側偺偱偡丅
丂偟偐偟偦傟偱傕丄傗偼傝幐嬈偺捈愙偺塭嬁偼戝偒偄偲巚偄傑偡丅幐嬈棪偲斊嵾棪偺悇堏傪夵傔偰愜傟慄僌儔僼偱尒偰傒傞偲丄偙傫側偺偱偡丅
巹傕偦傟側傝偵儅僋儘宱嵪巜昗偺僌儔僼傪偄傠偄傠尒偰偒偰偄傑偡偑丄斊嵾棪偺僌儔僼偵偙傫側偵宍偑帡偰偄傞傕偺偼丄忋壓媡偵偟偨偺傕娷傔偰丄幐嬈棪埲奜偵偼巚偄摉偨傝傑偣傫丅
丂嵟屻偵丄偙偺場壥娭學傪榑偠傞偙偲偵偮偄偰偼丄幐嬈幰傪斊嵾幰梊旛孯埖偄偟偰嵎暿偟偰偄傞偺偱偼側偄偐偲偺偛斸敾傕尒傜傟傑偡丅彮側偔偲傕巹屄恖偺堄恾偲偟偰偼丄偦偺傛偆側撉傒曽偼杮堄偲偼惓斀懳偱偡丅恖娫偼扤偱傕偨偄偰偄偼慞椙偱偁傝丄斊嵾側偳斊偟偨偄偲偼巚傢側偄傕偺偱偡丅偱傕丄屄恖偺搘椡偱偼偳偆偟傛偆傕側偄宱嵪偺忦審偵傛偭偰幐嬈偟丄傑偲傕偵嬺偭偰偄偔偙偲偺偱偒側偄忬嫷偵偍偐傟傞恖偑弌偰偄傞傢偗偱偡丅偦偺拞偱丄摜傒巭傑偭偰懴偊傞懡偔偺恖乆偼梍傔傜傟丄懴偊傜傟側偔偰斊嵾偵庤傪愼傔偨偛偔堦晹偺幰偼愑傔傜傟傞偺偼偨偟偐偵摉慠偱偡偑丄偟偐偟偙偺屻幰偺恖払傕丄宱嵪忦審偑堘偭偰偄傟偽丄慞椙側巗柉偲偟偰堦惗傪偍偔偭偨偼偢偩偲巚偭偰偄傑偡丅
丂幐嬈幰偲偄偆偺偼丄柉懓惈傗恎暘傗惈暿偲堘偭偰丄屄恖偺懏惈偱傕側偄偟丄懡偔偺応崌屄恖偺愑擟偱側偭偨傢偗偱傕側偄丅柍嶔傗夁偭偨惌嶔偱嶌傜傟傞傕偺偱偡丅偦偟偰丄柉懓惈傗恎暘傗惈暿偲堘偭偰丄杮棃偼柍偔偡偙偲傪傔偞偟偰惌嶔偑偲傜傟傞傋偒傕偺偱偡丅斊嵾傪嫵堢傗摴摽偺偣偄偵偟偰恀偺尨場傪曻抲偡傞偙偲偙偦丄堦晹偺恖乆偵晄岾側嫬嬾傪嫮偄傞嵎暿偵偮側偑傞偺偱偼側偄偐偲巚偭偰偄傑偡丅
******************************
丂偝偰丄慜夞偺僄僢僙乕偱偼丄師偺嶰偮偺幚徹儌僨儖傪徯夘偟傑偟偨丅
儌僨儖A乽扨弮儌僨儖乿丗斊嵾擣抦審悢傪偦偺擭偺幐嬈棪偱夞婣偟偨傕偺丅
儌僨儖B乽惔悈儌僨儖乿丗斊嵾擣抦審悢傪夁嫀4擭偺幐嬈棪偺暯嬒偱夞婣偟偨傕偺丅
儌僨儖C乽徏旜儌僨儖乿丗斊嵾擣抦審悢傪偦偺擭偺幐嬈棪偲丄4丒5丒6擭慜偺幐嬈棪偺暯嬒偲偺擇愢柧曄悢偱夞婣偟偨傕偺丅
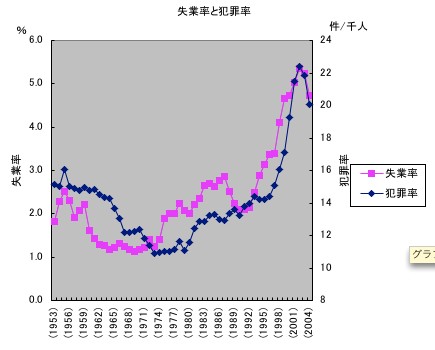
慜夞偍尒偣偟偨寢壥偼旕忢偵傛偐偭偨偺偱偡偑丄忋偵彂偒傑偟偨捠傝丄僟乕價儞丒儚僩僜儞斾偑偲偰傕掅偔丄岆嵎崁偵惓偺宯楍憡娭偑偁傝傑偡丅偡側傢偪丄
儌僨儖A 0.352丄儌僨儖B 0.309丄儌僨儖C 0.525
偱偟偨丅巆擮偱偟偨丅
丂偲偙傠偱丄偄偨偩偄偨偛斸敾偺拞偵丄斊嵾傪乽擣抦審悢乿偱應傞偺偼偍偐偟偄丄乽棪乿偵偡傞傋偒偩偲偄偆偺偑偁傝傑偟偨丅慜夞偺僄僢僙乕偱偼丄乽棪乿偱傗偭偨傜傕偭偲幚徹惉愌偼傛偔側傞偲梊憐偟偨偺偱偡偑丄幚嵺傗偭偰傒偨傜丄庒姳埆偔側傝傑偟偨丅傑偁丄偁傑傝曄傢傝偼偟傑偣傫偑丅
丂忋婰嶰儌僨儖偺旐愢柧曄悢傪乽恖岥愮恖偁偨傝偺斊嵾擣抦審悢乿偲偄偆堄枴偱偺乽斊嵾棪乿偵曄偊偰夞婣暘愅偡傞偲偙偆側傝傑偟偨丅
儌僨儖A丂娤應悢52(1953-2004)
丂丂斊嵾棪=9.517+1.925亊偦偺擭偺幐嬈棪
丂廳寛掕學悢偼0.653丄掕悢崁偲學悢偺p抣偼丄偦傟偧傟丄1.55亊10-23丄4.37亊10-13丄僟乕價儞丒儚僩僜儞斾偼丄0.153丅
儌僨儖B丂娤應悢49(1956-2004)
丂丂斊嵾棪=8.729+2.286亊夁嫀巐擭娫偺幐嬈棪偺暯嬒
丂廳寛掕學悢偼0.749丄掕悢崁偲學悢偺p抣偼丄偦傟偧傟丄2.12亊10-22丄1.01亊10-15丄僟乕價儞丒儚僩僜儞斾偼丄0.165丅
儌僨儖C丂娤應悢43(1962-2004)
丂丂斊嵾棪=6.377+2.049亊偦偺擭偺幐嬈棪+1.389亊4丒5丒6擭慜偺幐嬈棪偺暯嬒
丂廳寛掕學悢偼0.834丄掕悢崁偲戞1學悢丄戞2學悢偺p抣偼丄偦傟偧傟丄4.65亊10-12丄1.33亊10-5丄3.43亊10-8丄僟乕價儞丒儚僩僜儞斾偼丄0.243丅
丂寛掕學悢傗p抣偼丄偙傟偱傕廫暘偄偄抣側偺偱偡偑丄傗偼傝丄僟乕價儞丒儚僩僜儞斾偑掅偡偓偰丄岆嵎偺惓偺宯楍憡娭偑帵偝傟偰偄傑偡丅
丂偙偺栤戣傪僋儕傾偡傞偨傔偵丄僐僋儗儞丒僆乕僇僢僩朄偲偄偆偺偑偁傝傑偡偑丄幚偼丄巹偼寁検宱嵪妛偺愱栧偱偼側偄偺偱丄寁検暘愅偺僷僢働乕僕僣乕儖側偳傪帩偭偰偄側偄偺偱偡丅僄僋僙儖偵偼偦傫側偺偼嵹偭偰偄側偄偟丅
丂偦偙偱傑偢峫偊偨偺偑丄導暿僨乕僞傪廤傔偰堦帪揰偱僋儘僗僙僋僔儑儞偺夞婣暘愅傪偡傞偙偲偱偟偨丅偲偙傠偑導暿偺幐嬈棪偺僨乕僞偲偄偆偺偼丄乽楯摥椡挷嵏擭曬乿偱曬崘偝傟偰偄傞偺偱偡偑丄僂僃僽偱偼偲傟傑偣傫丅搚擔僙儞僞乕帋尡偱捛傢傟偰丄寧梛擔偵側偭偰偐傜恾彂娰偱尒偮偗偰偒偰丄寧梛堦擔偼偙偺暘愅偱旓傗偟偨偺偱偟偨偑丄寢榑偼偳偆傗偭偰傕幐攕偱偟偨丅導暿偺僋儘僗僙僋僔儑儞偱偼憡娭偼尒弌偣側偄偲偄偆偙偲偱偡丅
丂偦偙偱丄梻壩梛擔偼丄僐僋儗儞丒僆乕僇僢僩朄傪帋傒傞偙偲偵偟傑偟偨丅嫵堳媥宔幒偵偁傞僷僜僐儞偺SPSS偵偼擖偭偰偄傞偩傠偆偲巚偭偨偺偱偡丅
丂偲偙傠偑丒丒丒丄擖偭偰偄傑偣傫偱偟偨丅
丂偙偆側傝傖堄抧偩丅偲偄偆偙偲偱丄僄僋僙儖偱寁嶼偟偰丄抣偑廂懇偡傞傑偱壗夞傕夞婣暘愅傪孞傝曉偡乽恖椡僐僋儗儞丒僆乕僇僢僩乿偵僠儍儗儞僕偟偨偺偱偡丅偦偟偨傜壗夞傕儈僗偑尒偮偐傝丄偟偐傕孞傝曉偟偺弶婜偱儈僗偭偨傜丄孞傝曉偟寁嶼傪嵟弶偐傜傗傝捈偝側偗傟偽側傜側偄偲偄偆偙偲偱丄偙傟傕傑偨壥偰偟側偔帪娫偑偐偐傝傑偟偨丅偦偟偨傜偙傫側偺偵側傝傑偟偨丅
儌僨儖A丂娤應悢51(1954-2004)
丂丂斊嵾棪=10.53+1.525亊偦偺擭偺幐嬈棪+0.904亊慜婜偺岆嵎
丂廳寛掕學悢偼0.334丄掕悢崁(1-兿傪偐偗偨傕偺)偲學悢偺p抣偼丄偦傟偧傟7.83亊10-11丄8.81亊10-6丅
儌僨儖B丂娤應悢48(1957-2004)
丂丂斊嵾棪=8.323+2.22亊夁嫀巐擭娫偺幐嬈棪偺暯嬒+0.951亊慜婜偺岆嵎
丂廳寛掕學悢偼0.354丄掕悢崁(1-兿傪偐偗偨傕偺)偲學悢偺p抣偼丄偦傟偧傟0.0006丄8.43亊10-6丅
丂儌僨儖C偼丄孞傝曉偟寁嶼偑廂懇偣偢丄偲偆偲偆兿偑1傪挻偊偰偟傑偭偨偺偱偁偒傜傔傑偟偨丅忋擇偮偺寢壥偼丄p抣偑偲偰傕掅偄偺偱丄廫暘憡娭偑偁傞偙偲偼尵偊傑偡丅寛掕學悢偼嶰妱傕偁傟偽屼偺帤偱偡丅
丂嶶晍恾偼偙傫側姶偠偵側傝傑偡丅儌僨儖B偺傕偺偱偡丅墦椂偟偰30搙偖傜偄偵偐偄偰偍偒傑偡(徫)丅
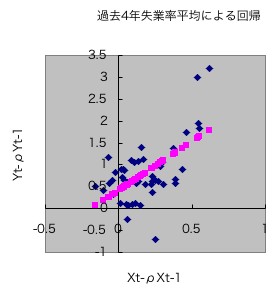
丂偟偐偟偙傟偱傕枮懌偱偒側偄巹偼丄奺曄悢丄慜婜偐傜偺奒嵎偳偆偟傪夞婣暘愅偡傞偙偲傪帋傒傑偟偨丅奒嵎偵偡傞偲宯楍憡娭偼側偔側傝傗偡偄偐傜偱偡丅偡傞偲偙偆側傝傑偟偨丅(埲壓4儌僨儖偺僟乕價儞丒儚僩僜儞斾偼岆嵎偺宯楍憡娭偺懚嵼傪帵偟偰偄傞丅劅劅08擭1/28)
儌僨儖A'丂娤應悢51(1954-2004)
丂丂斊嵾棪偺奒嵎=0.025+1.24亊幐嬈棪偺奒嵎
丂廳寛掕學悢偼0.212丄掕悢崁偲學悢偺p抣偼丄偦傟偧傟丄0.77丄0.00068丄僟乕價儞丒儚僩僜儞斾偼丄1.183丅
丂掕悢崁偼桳堄偱偼側偄偺偱丄掕悢崁傪偮偗側偄惂栺傪偍偄偨夞婣暘愅傪偟偰傒傞偲丄偙偆側傝傑偟偨丅
儌僨儖A''丂娤應悢51(1954-2004)
丂丂斊嵾棪偺奒嵎=1.262亊幐嬈棪偺奒嵎
丂廳寛掕學悢偼0.226丄學悢偺p抣偼0.00037丄僟乕價儞丒儚僩僜儞斾偼丄1.188丅
儌僨儖B'丂娤應悢48(1957-2004)
丂丂斊嵾棪偺奒嵎=-0.0145+0.842亊崱婜幐嬈棪偲夁嫀4擭暯嬒幐嬈棪偲偺嵎
丂廳寛掕學悢偼0.281丄掕悢崁偲學悢偺p抣偼丄偦傟偧傟丄0.869偲0.0001丄僟乕價儞丒儚僩僜儞斾偼0.905丅
丂傗偼傝掕悢崁偑桳堄偱側偄偺偱丄掕悢崁傪偮偗側偄惂栺傪偍偄偨夞婣暘愅傪偡傞偲丄偙偆側傝傑偟偨丅
儌僨儖B''丂娤應悢48(1957-2004)
丂丂斊嵾棪偺奒嵎=0.831亊崱婜幐嬈棪偲夁嫀4擭暯嬒幐嬈棪偲偺嵎
丂廳寛掕學悢偼0.298丄學悢偺p抣偼4.9亊10-5丄僟乕價儞丒儚僩僜儞斾偼0.904丅
丂偳傟傕憡娭偑桳堄偱偡丅偟偐傕丄奒嵎偳偆偟偵偡傞偲掕悢崁偑側偔側傞偲偄偆偙偲偼丄幐嬈棪偑憹偊偨擭偼斊嵾棪偑憹偊傞丄幐嬈棪偑尭偭偨擭偼斊嵾棪偑尭傞偲偄偆娭學偑偁傞偲偄偆偙偲偱偡丅
丂埲忋偺寢壥偱丄斊嵾偲幐嬈棪偺憡娭偼廫暘幚徹偝傟偰偄傞偺偱偡偑丄側傫偐枮懌偱偒傑偣傫偱偟偨丅
堦搙嬨妱偺枴傪偟傔偰偟傑偆偲丒丒丒
傑偨偦傟傪栚偵偡傞傑偱傗傔傞婥偑偟側偔側偭偨偺偱偡丅
丂偦偟偰丄幚偵偄傠偄傠偺幃傪帋偟丄偮偄偵偨偳傝偮偄偨偺偑丄師偺儌僨儖偱偟偨丅
儌僨儖X丂娤應悢51(1954-2004)
丂丂ln(斊嵾棪)=0.192+0.910亊ln(慜婜斊嵾棪)+0.065亊ln(偦偺擭偺幐嬈棪)
丂廳寛掕學悢0.9605丄掕悢崁偲戞1學悢丄戞2學悢偺p抣偼丄偦傟偧傟丄0.046丄2.95亊10-28丄5.53亊10-5丄僟乕價儞丒儚僩僜儞斾偼1.36丅
丂偙傟偱偳偆偩偭丅乽嬨妱乿弌偟偨偧(徫)丅p抣傕嬌傔偰掅偔偰桳堄偩偧丅宯楍憡娭偺栤戣傕傑偁傑偁偲偄偆姶偠(仼僟乕價儞偺h偼1.760偱偟偨丅宯楍憡娭偑側偄偲偄偆壖愢偑5%偺桳堄悈弨偱婞媝偝傟傞偙偲偑側偄偨傔偵偼丄h偑1.96傛傝彫偝偔側偗傟偽側傜側偄偺偱丄偙傟偵偁偰偼傑偭偰偄傑偡丅偮傑傝丄偲傝偁偊偢宯楍憡娭偼側偄偲尵偭偰傛偄偲偄偆偙偲偵側傝傑偡丅偁偁傛偐偭偨丅劅劅08擭1/28)丅偁傑傝懳悢傪偲傞堄枴偼側偔偰丄僫儅偺悢抣偱傗偭偰傕偦傫側偵偙傟偲斾傋偰埆偔側偄偺偩偗偳丄偲傝偁偊偢堦斣偄偄寢壥偲偄偆偙偲偱丅
丂偮傑傝丄悽偺拞偺斊嵾偵偼姷惈偑偁傞偲偄偆偙偲偱偡偹丅摉弶儌僨儖偱岆嵎偺宯楍憡娭偑偱偨偙偲偺惓懱偼丄偙傟偩偭偨偺偱偼側偄偱偟傚偆偐丅
丂傂偲偮怱攝側偺偼丄傕偲傕偲斊嵾棪偲幐嬈棪偼憡娭偑傛偐偭偨傢偗偱偡偐傜丄偦傫側傕偺傪擇偮愢柧曄悢偵巊偭偰丄懡廳嫟慄惈偑婲偙偭偰偄側偄偐偳偆偐偲偄偆偙偲偱偡丅偦傟偱峫偊偨偺偱偡偑丄儌僨儖X偺幃偱偼丄戞1學悢偲戞2學悢偺榓偼偩偄偨偄1偵側傞偺偱丄偙傟偑丄ln(斊嵾棪)=兛+(1-兝)亊ln(慜婜斊嵾棪)+兝亊ln(偦偺擭偺幐嬈棪)偲偄偆幃偩偲傒側偡偲丄椉曈偐傜ln(慜婜斊嵾棪)傪堷偔偙偲偱丄偙傟偼丄
丂丂丂斊嵾棪偺憹壛棪=兛+兝亊ln(偦偺擭偺幐嬈棪乛慜婜斊嵾棪)
偲曄宆偱偒傑偡丅偦偙偱丄偙傟傪夞婣暘愅偟偰丄兛傗兝偺抣偑埨掕揑偐偳偆偐妋偐傔偰傒傟偽偄偄傢偗偱偡丅傗偭偰傒傞偲偙偆側傝傑偟偨丅
儌僨儖X'丂娤應悢51(1954-2004)
丂丂ln(斊嵾棪)-ln(慜婜斊嵾棪)=0.118+0.061亊ln(偦偺擭偺幐嬈棪乛慜婜斊嵾棪)
丂廳寛掕學悢0.2822丄掕悢崁偲學悢偺p抣偼丄偦傟偧傟丄3.93亊10-5丄6.03亊10-5丄僟乕價儞丒儚僩僜儞斾偼1.38丅
丂寛掕學悢偼偁傑傝崅偔側偄偗偳丄p抣偼偲偰傕桳堄偱偡丅偙偺掕悢崁偲學悢傪傒傞偲丄儌僨儖X偺傕偺偲偦傟傎偳曄傢偭偰偄傑偣傫丅儌僨儖X偺寢壥偼埨掕揑偲尵偊傞偲巚偄傑偡丅(偨偩偟傗偼傝偙偺儌僨儖傕岆嵎偺宯楍憡娭偑偁傞丅劅劅08擭1/28)
********************************
丂偝偰丄嵟屻偵巹傕丄斊嵾庬暿偺暘愅傪帋偟偰傒傑偟偨丅偲偄偭偰傕丄愞搻偲嶦恖偩偗偱偡偑丅
丂傑偢愞搻偱偡偑丄傎偲傫偳儌僨儖X偲摨偠幃偱丄斊嵾慡懱偲摨偠斀墳傪偟偰偄傑偡偹丅乽恖岥愮恖偁偨傝偺愞搻偺擣抦審悢乿傪乽愞搻棪乿偲偟偰丄夞婣暘愅偟偨傜丄師偺傛偆偵側傝傑偟偨丅
儌僨儖Y丂娤應悢49(1954-2002)
丂丂ln(愞搻棪)=0.0812+0.952亊ln(慜婜愞搻棪)+0.065亊ln(偦偺擭偺幐嬈棪)
丂廳寛掕學悢0.962丄掕悢崁偲戞1學悢丄戞2學悢偺p抣偼丄偦傟偧傟丄0.471丄2.75亊10-23丄0.0011丄僟乕價儞丒儚僩僜儞斾偼1.89丅
丂掕悢崁偩偗偑桳堄偱偼偁傝傑偣傫偑丄懠偼偡傋偰廫暘桳堄偱丄寛掕學悢傕96亾丄岆嵎偺宯楍憡娭傕偁傝傑偣傫(僟乕價儞偺h偼0.328偟偐側偄偺偱丄傗偼傝宯楍憡娭偑側偄偲偄偆壖愢偼庴偗擖傟傜傟傑偡劅劅08擭1/28)丅斾傋偰傒偨傜丄儌僨儖X偲學悢偼傎傏摨偠偱偡偹丅摿偵丄幐嬈棪偵偐偐傞學悢偑傄偭偨傝摨偠偩偲偄偆偙偲偑摿昅偝傟傑偡丅偮傑傝幐嬈棪偺摨堦偺曄壔偵崌傢偣偨斊嵾擣抦審悢慡懱偺曄壔棪偼愞搻偺曄壔棪偲摨偠偩偲偄偆偙偲偱偡丅
丂偱偼丄嶦恖偺傛偆側斊嵾偼幐嬈棪偲偼柍娭學側偺偱偟傚偆偐丅忋婰eliya偝傫偲PyTest偝傫偱暘愅寢壥偑怘偄堘偭偰偄傞偲偙傠偱傕偁傝傑偡丅幚偼丄乽恖岥愮恖偁偨傝偺嶦恖偺擣抦審悢乿傪乽嶦恖棪乿偲偟偰丄儌僨儖X宆偺幃偱夞婣暘愅偟偨傜丄慜婜偺嶦恖棪偩偗偱愢柧偑偮偄偰偟傑偄丄幐嬈棪偺學悢偼慡偔桳堄偱偼側偔側傝傑偡丅偱偼丄eliya偝傫偑惓偟偔丄PyTest偝傫偼娫堘偭偰偄傞偺偱偟傚偆偐丅
丂傕偆彮偟徻偟偔専摙偡傞偨傔偵丄嶦恖審悢偺悇堏傪愜傟慄僌儔僼偵偟偰丄幐嬈棪偺僌儔僼偲偁傢偣偰挱傔偰傒傑偟傚偆丅
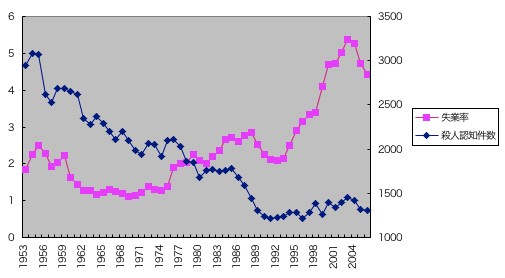
丂堦尒偟偰偍傢偐傝偺偲偍傝丄愴屻嶦恖偼堦娧偟偰尭彮偟偰偄傑偡丅恖嶦偟偽偐傝偱悽偺拞偑偩傫偩傫暔憶偵側偭偰偒偰婋尟偩婋尟偩偲偄偆捠擮偑丄偄偐偵偄偄偐偘傫側傕偺偐丄偙傟傪尒傟偽堦栚椖慠偱偡丅壗偑愴屻嫵堢偺偣偄偩偲巚偄傑偡丅
丂偦傟偼偲傕偐偔丄傛偔尒偰傒傞偲丄嶦恖擣抦審悢偺嵶偐偄曄摦偼丄傗偼傝幐嬈棪偺曄摦偲僔儞僋儘偟偰偄傞傛偆偵尒偊傑偡丅偦偙偱偙傟傪幚徹偟偰傒傑偟傚偆丅eliya偝傫偑偍巊偄偵側偭偨憤柋徣摑寁嬊偺挿婜僨乕僞偼2002擭偱廔偭偰偄傞偺偱丄巆傝偼丄寈嶡挕偺摑寁僒僀僩偐傜枅擭偺斊嵾曬崘傪挷傋偰丄2006擭傑偱宲偓懌偟偰偄偒傑偟偨丅
儌僨儖Z丂娤應悢54(1953-2006)
丂丂嶦恖擣抦審悢=86716.82+193.84亊偦偺擭偺幐嬈棪-43.1亊僩儗儞僪(惣楋擭)
丂廳寛掕學悢0.964丄掕悢崁偲戞1學悢丄戞2學悢偺p抣偼偦傟偧傟丄4.52亊10-35丄6.81亊10-14丄1.86亊10-34丄僟乕價儞丒儚僩僜儞斾偼1.00丅
丂傑偨嬨妱(徫)丅寛掕學悢偲p抣偩偗尒偨傜丄桳堄傕桳堄偱偡丅偨偩偟丄僟乕價儞丒儚僩僜儞斾偼旝柇側抣偱丄岆嵎偺宯楍憡娭偑側偄偲偼尵偄愗傟傑偣傫(偙傫側傕偺偱偼彫偝偡偓傑偡丅僶儕僶儕宯楍憡娭偟偰偄傑偡劅劅08擭1/28)丅偦偙偱丄儌僨儖Z偺幃偺1擭僘儔偟偨傕偺傪嵍曈偳偆偟塃曈偳偆偟堷偄偨奒嵎偺幃傪夞婣暘愅偡傞偲丄僩儗儞僪崁偺學悢偑掕悢崁偵側傝丄戞1學悢偑偦偺傑傑學悢偵側偭偰偄傞偼偢偱偡丅偡傞偲丄師偺傛偆側寢壥偑偱傑偟偨丅
儌僨儖Z'丂娤應悢53(1954-2006)
丂丂嶦恖擣抦審悢偺奒嵎=-38.49+157.23亊幐嬈棪偺奒嵎
丂廳寛掕學悢0.137丄掕悢崁偲學悢偺p抣偼偦傟偧傟丄0.0095丄0.0063丅僟乕價儞丒儚僩僜儞斾偼2.12丅
丂寛掕學悢偼掅偄偱偡偑丄掕悢崁偲學悢偼桳堄偱偡丅岆嵎偺宯楍憡娭偼慡偔偁傝傑偣傫丅偙偺掕悢崁偲學悢傪儌僨儖Z偺傕偺偲斾傋偰傒傞偲丄傑偁傑偁偄偄慄偄偭偰偄傞偲尵偊側偄丠
丂偩偐傜丄忋偺愜傟慄僌儔僼傪尒傞偲丄暯惉晄嫷埲崀丄嶦恖偼壓偘巭傑偭偰墶偽偄孹岦偵側偭偰偄傑偡偑丄偙偺晄嫷偑側偗傟偽偙偺傑傑壓偑傝懕偗偨壜擻惈偑崅偄偲巚偄傑偡丅幉偺堦斣壓偺栚惙傝偼僛儘偱偼側偄偺偱丄傑偩傑偩壓偑傞梋抧偼偁偭偨偼偢側偺偱偡丅
丂巹偼偙傟偱偲傝偁偊偢懌傪愻偄傑偟傚偆丅惔悈孨偼棃擭搙偺懖榑偱懕偒傪傗偭偰偔傟傞偱偟傚偆偗偳丄屼娭怱偺偁傞偐偨偼偦傟偵偐傑傢偢丄偳傫偳傫傗偭偰壓偝偄丅愱栧偺偐偨偼偠傔丄巙偺偁傞偐偨偼丄娗夑峕棷榊偝傫偺僨乕僞儀乕僗峔抸僾儘僕僃僋僩偵惀旕嫤椡偟偰傗偭偰壓偝偄丅桳堄媊側偺偵屒撈側嶌嬈偵偍搟傝偺傛偆側偺偱丅
********************************
丂嵟屻偵丄慜夞僄僢僙乕偺僞僀僩儖乽斊嵾偺嬨妱偼幐嬈棪偱愢柧偱偒傞乿偼丄慜夞偺僄僢僙乕偺捛婰偺嵟屻偱傕庍柧偟傑偟偨偲偍傝丄昐枩審偺斊嵾偺偆偪嬨廫枩審偑幐嬈桼棃偲偄偆傛偆側岆夝傪梌偊偨揰偱丄巚椂偺愺偄昞尰偩偭偨偲斀徣偟偰偄傑偡丅傕偪傠傫丄乽斊嵾悢偼幐嬈棪偵傛偭偰嬨妱偑偨偺偁偰偼傑傝偱愢柧偱偒傞乿偲偄偆堄枴偱偡丅
丂惔悈孨偺榑暥偺僞僀僩儖偼乽幐嬈棪偲斊嵾擣抦悢偵偮偄偰乿丅傾僆傝傕僸僱傝傕側偄丅傕偭偲僸僱傝側偝偄丄僸僱傝側偝偄丒丒丒丅妛惗偺曽偑傛傎偳恀潟偱偡偐偦偆偱偡偐丅
丂
丂
乽嵟嬤姶偠傞偙偲乿栚師傊
儂乕儉儁乕僕傊傕偳傞